

18 Oct 2021 Embracing the Beauty of Concurrency in Golang
I was recently working on a small ETL project that read data from a data source, processed it, and wrote it to storage. The software worked correctly, but as the volume of data it was processing grew, the execution time would also grow. This was a problem for the business.
Kent Beck once said that, when building software, the order of priorities should be “Make it work, make it right, make it fast“. In keeping with this philosophy, my priority on the project so far had been to first get something working, and then ensure it was going about it the right way. However, it was now time to move onto making it fast. In this post I’ll show you how I did it using Go.
Problem Analysis
The basic flow of activities for the system was:
- Read the data from the source
- Process as-per business rules
- Write the data into the storage
- Continue until there is no more data to be processed.
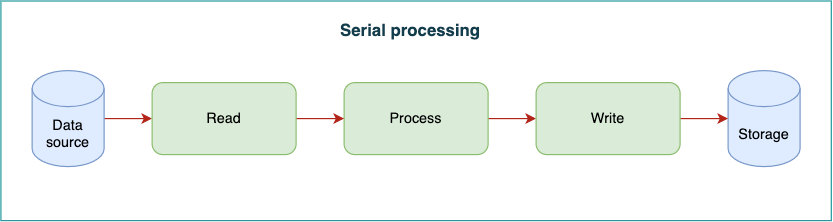
You may have already spotted the bottleneck in this flow. It assumes that we have to execute the read, process, and write serially. When any of these tasks is executing, the other two tasks are blocked and waiting.
If the data items being processed by the tasks were interconnected in some way, optimisation would be tricky. For example, if items needing to be written out in the same order they were read in, that would be more difficult to speed up.
However, in this case I knew that each data item could be handled independently, with no reference to past or future items. This made our project an excellent candidate for concurrent processing.
Solution Design
Since the solution seemed to be moving in the direction of concurrency, it was now time to think about how we might manage the execution of concurrent tasks, as well as any communication between them.
To do this, it was helpful to imagine the system as a production line, where each unit of work must be read, then processed, then written out. Each data unit could only be handled by one task at a time; but at the same time, each step could be busy with a different piece of work.
When workers are allocated in a production line, each worker only performs one step of the full job. When the output of that step is complete, the worker passes it to the next worker in the line. Some steps can be done quickly, while others are slow. The problem with a serial line is that a slow worker will hold up the whole line.
To resolve this, we can introduce some sort of communication medium as a buffer between workers. This means workers just need to get the inputs for their next job from the buffer, rather than directly from another worker. Similarly, when a worker is done, they put their output into the buffer, rather than passing it directly onto another worker.
This decoupling enables multiple workers to perform the same sort of task concurrently.
Thinking in these terms, we would introduce these “buffers” to the application architecture as follows:

Of course, this isn’t really much value yet, as everything is still serialised. To see the benefits, we need to identify what work can be parallelised.
In the case of our system, further analysis identified that both the processing and write tasks were the most time-consuming, whilst reads weren’t really slowing us down. Consequently, to speed things up, we could add more workers for these slower tasks:

Implementing It
Having identified the cause of the problem, and a concurrency model that could deal with it, the next step was to choose a programming language and start coding.
My choice of language was Go, because it supports concurrency natively via the concepts of goroutines and channels.
A goroutine is a function that can run concurrently with other functions. Goroutines are like threads, but the cost of creating a goroutine is tiny compared to an actual thread. Therefore it is easy to create and run thousands of them concurrently. For more detailed information about the difference between a goroutine and thread, see here.
A channel is a way for goroutines to communicate with one another and synchronize their execution. This is probably enough for you to understand the remainder of this article, but for a deeper understanding of how goroutines and channels relate to each other, I recommend you read this.
In our case, goroutines would encapsulate the tasks, and channels would be the communication medium by which data was passed from one task to the next. Once set up in this manner, the Go runtime could then take care of everything else.
An example project
Unfortunately I can’t share with you the source code for my client project. However, to demonstrate the basic concepts in action, I built an example application that reads a flat file, processes it, and write the results to Redis. The performance improvements of parallelising this example application are similar to what I saw in my client project.
The example application’s flat file contains lines of fake user records. Each record contains an id, first name and last name. Here’s a sample of what the file looks like:
dd8ae78452ec471a841c57bc138699ff,Gina,Nicolas 17d2c73fe7854332a253ccca9d863147,Morris,Bartoletti 90ccdf5923d84e0a9d0ff8a59c278d28,Chelsey,Adams da0d8357555c421b9b6857c609d273cc,Demetris,Welch bde2139d238545b68c1bb7a4f79e865a,Gracie,Schultz 95417d16e04040fe8fc8f2008a7feef2,Myrna,Daugherty ...
To process the file, the Go program is structured like this:

You can see that, because I know that reading data from a file is pretty quick, I’ve only started one “Reader” goroutine. This sends data to a “Read” channel.
Next, because I know that processing data is slow, I’ve created several “Process” goroutines which receive the data from the “Read” channel, manipulate it, and send it on to the “Write” channel.
Finally, because writing data to Redis is also a time consuming task, I spawned multiple Writer goroutines to pull from the “Write” channel and write to Redis.
By default, since the main goroutine does not wait for other (non-main) goroutines to complete, the program will exit as soon as the main function invocation returns, even if the other goroutines have not finished executing yet. To let all the other goroutines complete, we have a “Exit” channels. The main goroutine waits until all the other goroutines have posted to this channel before it exits the process.
Another way to achieve this exit synchronisation is to use a sync.WaitGroup, although I didn’t do that in this case.
Measuring the example project
Our final goal is to verify that the concurrency model performs better than serial processing. Here are the execution times in minutes and seconds when running the example project on a quad-core machine where the process was able to use 8 logical CPUs:
| Number of lines | Serial processing | Concurrency (1 writer goroutine) | Concurrency (100 writer goroutines) | Concurrency (1000 writer goroutines) |
|---|---|---|---|---|
| 100,000 lines | 2:00 | 1:53 | 0:14 | 0:13 |
| 1,000,000 lines | 19:34 | 18:31 | 2:32 | 2:29 |
As you can see from the table, with one goroutine running for each task, there was little difference. However, with 100 goroutines, the time was approximately 8 times faster. That was quite an astonishing outcome, given the minimal code changes involved. Interestingly though, going up to 1000 writers did not make much more difference.
As an additional experiment, I ran this application on a dual-core machine with 4 logical CPUs:
| Number of lines | Concurrency (1 writer goroutine) | Concurrency (100 writer goroutines) | Concurrency (1000 writer goroutines) |
| 100,000 lines | 2:09 | 0:34 | 0:27 |
| 1,000,000 lines | 25:44 | 4:36 | 5:07 |
Whilst results will vary for different data sources, processing steps or storage types, the benefit of concurrency is clear. However, it’s important to recognise that, depending on your application, you may need to experiment to find the optimal number of goroutines.
Conclusion
Concurrency reduces the waiting and response times of your app, and increases CPU utilisation and efficiency. A single giant task can be deconstructed into many smaller tasks, which can then be executed concurrently.
The beauty of concurrency in Golang is that, if you have done your analysis correctly and properly understand the concepts, it is straightforward to implement.
However, it’s important to remember that, even if the implementation is easy, the analysis and understanding takes time. Consequently, before jumping in you should think about whether the benefits of optimisation outweigh the costs. For example, if the business task is not time sensitive, it might not be worth optimising your implementation, even if you suspect it is not as efficient as it could be. In the words of Donald Knuth:
“The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimisation is the root of all evil (or at least most of it) in programming.”
From “The Art of Computer Programming“
I hope you found this blog beneficial.
No Comments