

27 Mar 2026 Moving Bedrock Solutions to Production with Defence in Depth Beyond Standard Guardrails
Only 5% of Generative AI tools reach production, and there is a good reason for it.
The new world of AI tools is set to storm the market. In only the first half of 2025, more than $44 Billion has already poured into GenAI investment and just about every organisation is looking to capitalise on it. So where are the results?
While MIT’s project NANDA report gives a few reasons for the hesitancy, i.e. brittle workflows and lack of contextual learning, one recurring pain point is trust and privacy. General sentiment for AI adoption is hesitant at best with many reports documenting instances of lawyers blindly trusting fake case law for their legal arguments, Samsung employees leaking top secret data to ChatGPT, and Grok exposing more than 370,000 conversations to Google’s search engine results. These realities are alarming and give pause to the general public who are wondering if their private data is safe.
Dissecting “Guardrails”
Up until this point, Guardrails have largely been viewed as input-output filters aiming to screen prompt text and model responses for prohibited topics, harmful content, or sensitive data. In theory the model never sees what it shouldn’t, and neither does the user.
In their paper, Swiss Cheese Model for AI Safety, Shamsujjoha et al attempts to expand our understanding of guardrails to more than just input-output filters for prompts. Instead Shamsujjoha et al proposes a model that has had extensive adoption in other well matured industries such as aviation.
The analogy is as follows: Think of a single guardrail as a slice of swiss cheese – effective at blocking most threats, but riddled with holes that a determined attacker can find and exploit. Put one slice between you and a breach, and the gaps are obvious. But when stacking multiple slices on top of each other the odds of any single hole lining up all the way through drop dramatically. This is the essence of layered defence (also referred to as “Defense in Depth” in other contexts). No individual guardrail needs to be perfect, because the combined probability of every layer failing simultaneously becomes exponentially small.
With this principle in mind, Shamsujjoha et al lists several areas where guardrails can be applied to LLMs, but we’ll focus on the following:
- Quality attributes – Define what the guardrails protect, such as accuracy, privacy, security, and fairness, ensuring the system remains safe, reliable, and trustworthy.
- Actions – Describe how the guardrails operate, through mechanisms like blocking, filtering, or human review to prevent or correct unsafe behaviour.
- Targets – Specify where the guardrails are applied across the AI pipeline and its components, ensuring layered protection even if one safeguard fails.
Bedrock’s slice of the cheese
Amazon’s fully managed serverless AI platform, Bedrock, provides its own built-in guardrails you can configure when using their services.
The provided controls aim to reduce harmful outputs and protect sensitive information. These include tools such as:
- Content filters – Automatically detect and block harmful or sensitive content, helping ensure that model outputs remain appropriate and aligned with responsible AI guidelines. These filters have been recently expanded to include toxic image recognition and filtering.
- Denied topics and word filters – Restrict prompts or responses containing specific keywords or subjects, preventing the model from engaging in disallowed conversations or generating risky material.
- PII and custom regex masking – Identify and mask personally identifiable information or other custom patterns using regular expressions, reducing the risk of sensitive data exposure in both inputs and outputs.
- RBAC for Knowledge Bases – While this isn’t a built-in function of Bedrock Knowledge Bases, role-based access control (RBAC) can be achieved through metadata filtering.

The landscape of Bedrock’s available tools is continually evolving by improving content filters and denied topic measures, and expanding these capabilities to monitor code inputs and outputs. That being said, achieving production-grade security requires extending these capabilities into a broader defense-in-depth strategy.
Gaps organisations can’t ignore
On face value the Bedrock platform appears to be providing a reasonable comprehensive suite of tools to manage model security. However each individual control has it’s limitations and should be considered as part of a complete solution. For instance:
- The NLP and ML classifiers are not completely deterministic – there is a probabilistic nature to the classification of input, meaning slight wording changes could be the difference between successfully or unsuccessfully blocking bad content.
- Content filters rely on defined semantic patterns and tokens. If the content doesn’t match the pattern, it won’t be filtered. Bypassing these kinds of measures can often be trivial and certainly cannot be relied upon on their own.
- Regex or PII masking won’t stop a user from copying and pasting trade secrets or proprietary code. Topic denial and prompt engineering mechanisms only offer soft guardrails, their effectiveness is unquantifiable, and they risk blocking perfectly valid prompts.
- RAG-based searches in Bedrock Knowledge Bases can quickly shift from an asset to a liability when they enable the exfiltration of sensitive information. While data sanitisation is technically achievable, implementing it effectively at scale remains complex and costly.
- Per-user auditing, knowing who accesses what, and Role-Based Access Control (RBAC) enforcement for Knowledge Bases are technically feasible but require significant additional development. These capabilities should be natively supported and tightly integrated with AWS IAM, rather than relying on metadata filtering as a functional workaround.
- Policy actions triggered by guardrails are currently limited. Additional development is required where built-in event-driven workflows such as human-in-the-loop (HITL) or fallbacks would provide significant value.
Above all, Bedrock’s guardrail coverage represents just a few slices of Swiss cheese, which are applied almost exclusively to the model’s input and output. They only loosely extend to Knowledge Bases, and don’t reach areas that require custom development such as tool calls, memory, and the intermediate steps of chain-of-thought reasoning, all of which sit beyond Bedrock Guardrail’s reach entirely.
Swiss Cheese defence in practice
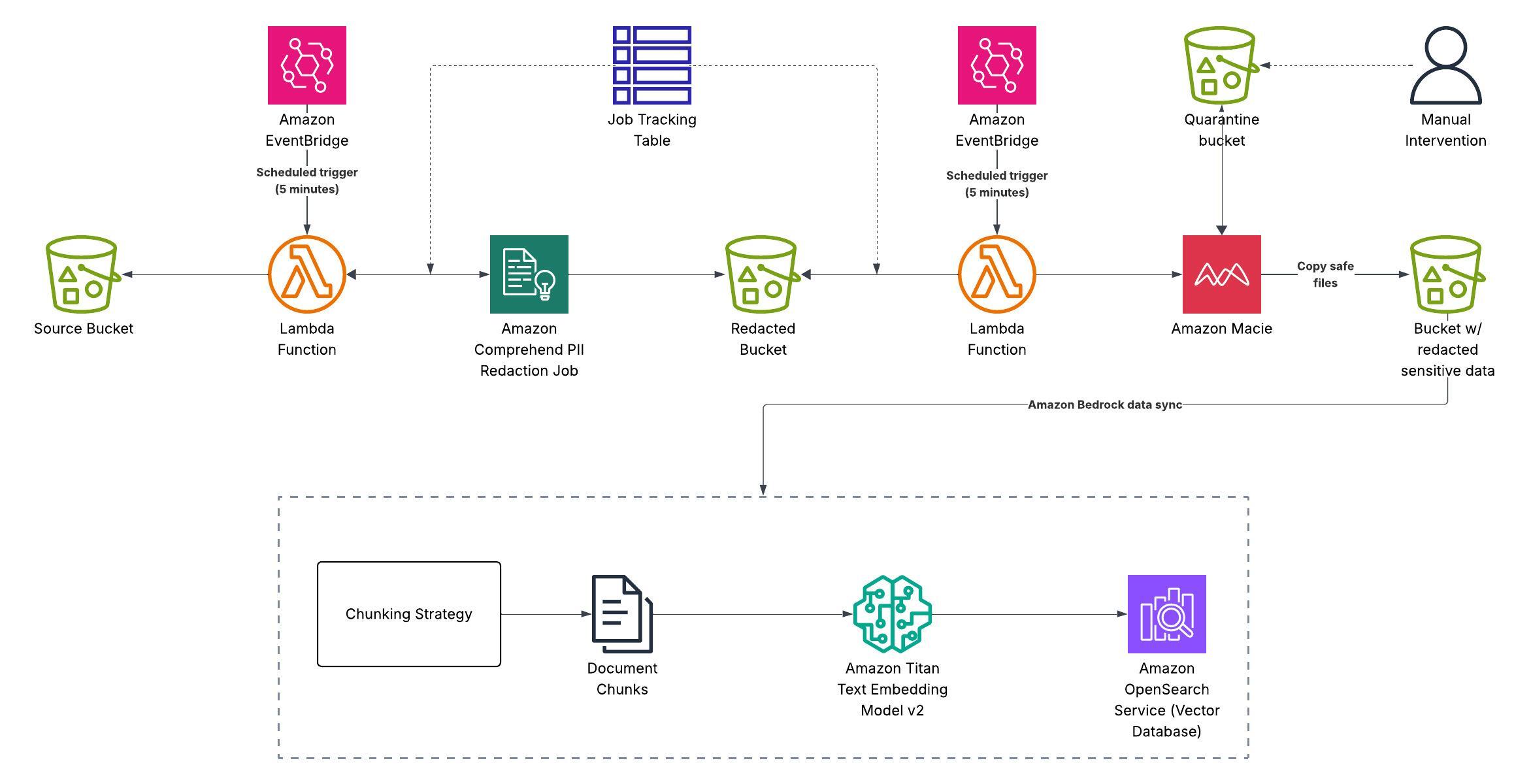
Applying layered defence in Bedrock means expanding well beyond Bedrock itself. AWS’s own blog on protecting sensitive data in RAG applications is a good starting point, describing a set of scenarios that together begin to address the following gaps:
- Sanitising reference data before it enters your vector database, using AWS Macie and Comprehend to identify and remove sensitive information before it ever gets encoded.
- Implementing RBAC through metadata tagging and filtering on the vector database, ensuring users can only retrieve the information they are actually permitted to see.
- Treating the LLM as an untrusted actor by default, enforcing strict authorisation on every tool call, applying deterministic input checks, and pairing this with solid data engineering and authentication practices to close the gaps that probabilistic guardrails will inevitably miss.
Where does that leave us?
The difficulty securing AI tools is having to implement entire security approaches across the application, which proves difficult and leaves many AI Proof-of-Concepts without a viable path to production. As it stands, most of the conversation currently revolves around MCP and accuracy. Whilst the grunt work of establishing real AI safety foundations remains to be done by each AI Practitioner.
The good news is the tools exist, but assembling them into something trustworthy still requires a large amount of heavy lifting that most AI projects simply haven’t budgeted for on their road to production. We absolutely need to start including time and budget for implementing guardrails, as AI security will remain a stack of Swiss Cheese slices, with every additional layer making your solution that bit more secure.
No Comments