

24 Feb 2021 Exploring Graph Databases with Amazon Neptune
For a long time, relational databases have been the answer to every data persistence need (whether they really suited the solution or not). In the previous decade, there has been an explosion of different types of database engines. This has been partly driven by data volume and access patterns not previously encountered. The other factor at play here has been the growth of the big cloud vendors. The centralisation of expertise has allowed these vendors to provide speciality database technology that would have previously been out of the reach of the middle-of-the-road enterprise organisations.
In this post I’m going to take a look at one of these new flavours of database: Graph Databases. As part of this we’ll take a look at Apache TinkerPop Gremlin and Amazon Neptune (the AWS Graph Database option)
What is a Graph Database and why would I use one?
No surprises here as it is in the name: Graph Databases store data in a way that makes it very easy to model relationships; it is called a graph. The kind of graph we are talking about comes from a branch of mathematics called graph theory; we are not talking about Excel and pie charts. In graph theory there are two primary constructs: we have nodes and edges. Nodes represent data entities, edges represent the relationships between them.
Why would I ever want to do this? Aren’t SQL joins good enough for anything? Well, not really. For some use cases, Graph Databases outshine relational databases. This is due to the fact that relationships between our data entities are stored in the database itself. With a relational database you either use JOIN commands at run-time or end up having many link tables to map relationships between entities.
A classic example is social networks. In the diagram below we have three people nodes and one band node:
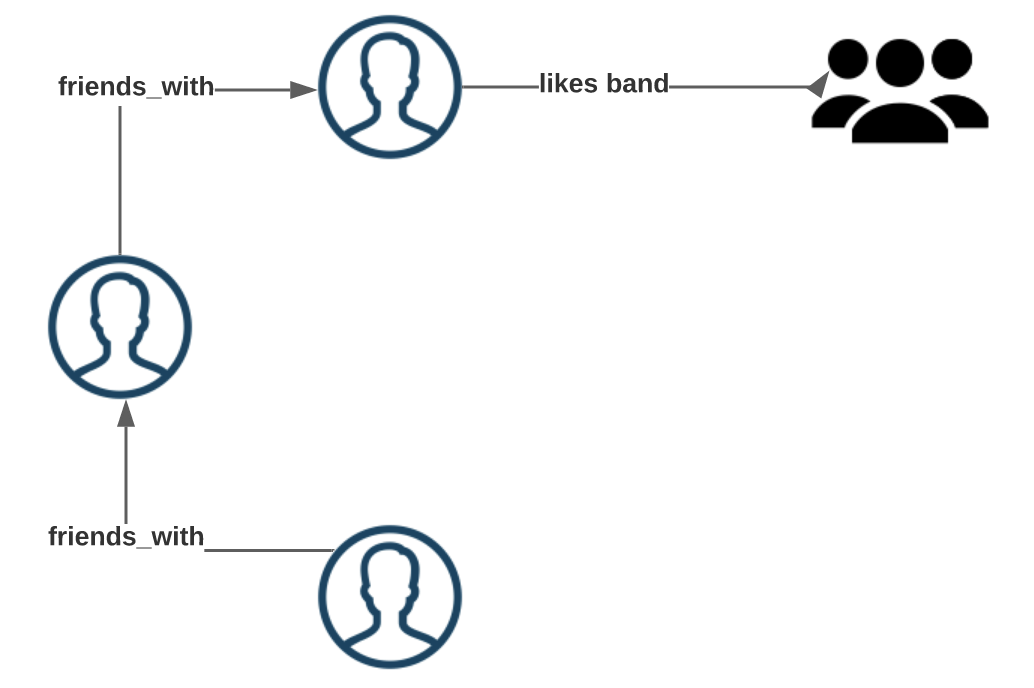
The edges (friends_with and likes_band) describe the relationship between entities. Having these entities mapped in this way makes it much more intuitive to reason about the relationships between your data. To make similar queries in a relational database rapidly becomes prohibitively expensive, especially as you scale up to millions of nodes and edges.
Rather than list use cases here, I am going to link to this page provided by Neo4j (one of the main Graph Database providers). It provides some fantastic ideas about suitable use cases for this technology.
Ok, enough conceptual information, let’s have a look at some examples. I’ll first run through some examples on my local machine, I’ll then spin up an Amazon Neptune database and replicate the same examples there.
Apache TinkerPop Gremlin
This is really a thing. Gremlin is a graph traversal language provided by the Apache Software Foundation. It is one of the major query languages for use with TinkerPop compliant graph databases.
Just a point of clarification here on Apache TinkerPop and Gremlin. TinkerPop can be thought of like JDBC for Graphs, it is an API specification that TinkerPop compliant databases must support in order to be TinkerPop compliant. Gremlin is one of the query languages for interacting with this API.
Conveniently the Gremlin package provides a local in-memory server we can run to play around with a local database.
Let’s dive in
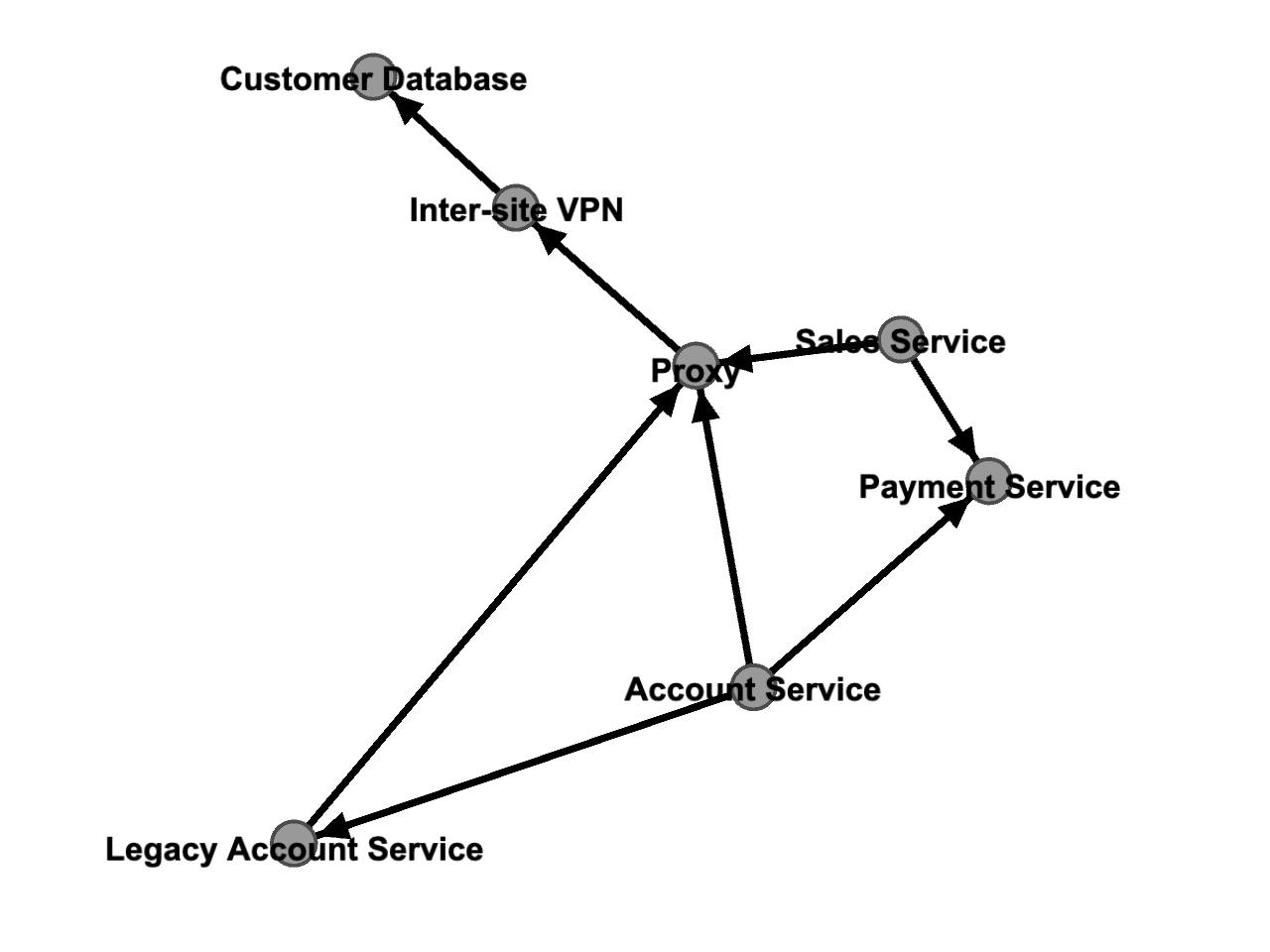
I’m going to propose a simple example here: an asset database that models the relationships between infrastructure and application services. The image below shows an example of this basic model. On the right, we have a number of application services running in an AWS account. These services communicate through a proxy and VPN to an on-premise customer database. The arrows on the edges between nodes demonstrate the direction of the dependency (i.e. the Account Service depends on the proxy, which depends on the VPN etc..):
Gremlin console installation
Getting Gremlin setup is really easy. All you need is a JVM installed (I’ve tried 8 and 11). You download and extract the Gremlin console from here. Once you have this extracted, browse to the bin/ directory in your terminal and run ./gremlin.sh
If all goes well, you’ll be greeted with the following:

Let’s load some data
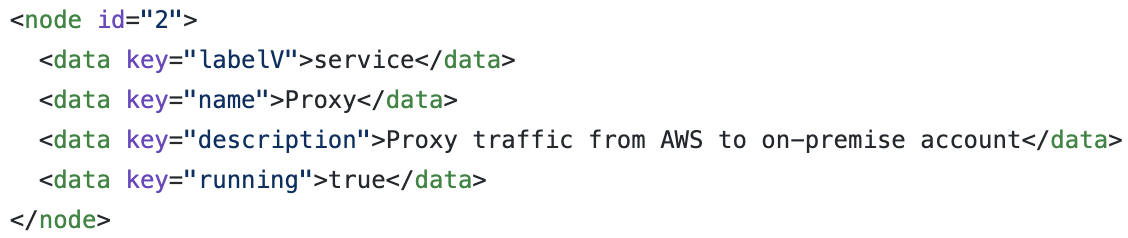
I’ve provided some data for our simple asset database in this GraphML file. GraphML is a common XML based data format for describing graph structures. The two most important parts to understand are our nodes:

and our edges:

In the above we have two example nodes (our Proxy and Account services). We map the Account Service as the source and our Proxy as the target in an edge. If you take a look at the GraphML file linked above you will see all the nodes, and the edges that describe the relationships between them.
To load my assets.graphml file I have copied it into /tmp and from the Gremlin console run the following commands:
graph = TinkerGraph.open()
graph.io(graphml()).readGraph('/tmp/assets.graphml')
g = graph.traversal()
We can see the result in the below screenshot: 7 vertices (nodes) and 8 edges have been loaded into the database:

Going over these commands:
- Line 1 opens a new in-memory instance of TinkerGraph (an in-memory implementation of TinkerPop).
- Line 2 reads our GraphML file and loads it into the database
- Line 3 instantiates a graph traversal source object. This will allow us to run traversal queries against this graph. A traversal query walks from node to node matching against our criteria.
What can we do now?
We have some data loaded. Let’s try some simple queries.
What is Sales Service connected to?

Cool! So we know the Sales Service has a direct dependency on our Proxy and Payment Service. What’s actually happening in the query though? Gremlin is a functional language, we can read the chained functions in the query from left to right. For starters we get our node named ‘Sales Service. “.out()” says to find all the nodes that are connected to our node in an outward direction. “.values(‘name’)” returns the name of each of these nodes. Finally, unfold() shows the results in a top to bottom list instead of one after the other in an array.
Which nodes connect to Payment Service?

This is a very similar query. Instead of “.out()” we use “.in()”, so this shows all nodes connected to our Payment Service node.
What paths are there from Account Services to Customer Database?

Interesting. We have two paths our Account Service can take to the Customer Database. Either directly, or it can send a query through the “Legacy Account Service” node. From a query point of view, the following is happening:
- Get the node named “Account Service”
repeat(out().simplePath()).until(has('name','Customer Database'))walks through the graph, starting from “Account Service”, until it gets to “Customer Database”. The simplePath() function means the traverser will not repeat its path through the graph (no loops).limit(10)means the traverser won’t walk further than 10 nodes deep when finding paths. This is important when dealing with dense complex graphs due to the possible performance impacts of traversing too deeply into the graph.- The
path()function transforms the traversal into a path, in this case by “name” of the node
Something more involved
For our final example, let’s do something that is relatively complex, but I think shows the power of a graph database for the right use case. Let’s say we are a network administrator and we want to know all the downstream services that depend on our VPN so we can communicate to the relevant owners about a planned outage. Keep in mind we have to find direct services, and all the direct sub-dependencies, because they will all be affected:

We can see all our dependent services. The query looks intimidating at first, but the SQL equivalent would be MUCH larger. Let’s have a look at what’s happening here:
- We start with our “Inter-site VPN” node and set it as “rootNode” so we can reference it later in the query
- We now repeatedly walk the paths of the in() nodes, We do this recursively until we have no more incoming nodes on that path
where(neq('rootNode'))means we don’t include our root node in our outputdedup()removes any duplicate nodes (i.e we could traverse the same node twice, we don’t want this in the list)- Finally we output the names of the services found
You may have noticed the __.in() and __.not(). Gremlin is based on Groovy, and the underscores are put in there to avoid clashing with native Groovy keywords.
Now we’ve had a look at the Gremlin language, let’s have a quick look at how to do similar things with the Amazon Neptune service.
Amazon Neptune
Amazon Neptune is a managed Graph Database service provided by Amazon. Much like the Amazon Aurora RDS service, you work with database clusters that have writers and readers for accessing data. More information can be found on the product page here. Most importantly for our purposes here, Neptune supports Gremlin natively, it also provides support for another query language called SPARQL, I won’t dig into that here.
Let’s setup a simple cluster and see what the experience is like.
A couple of things to note, Neptune is only available within a VPC and if you want to access other AWS services (for example S3 to load data), you will need to set up VPC endpoints to facilitate that. More information on that here.
There are a couple of pre-requisites to this part of the article. 1) You will want to have a VPC configured, I have a simple one configured with a private subnet that I will launch my cluster in and 2) You will want an EC2 instance running in the same subnet to access your cluster with (via the Gremlin console).
Creating a Neptune database
Navigate to the Neptune console and click “Create database”:

Note that I have just left my database engine as the default provided. Now give your database cluster a unique identifier:
For our purposes it makes sense to go with the “Development and Testing” template:
As this is just for demo purposes, I am going to with the smallest possible instance, which is a t3.medium:
No need for read-replicas in multiple availability zones for our demo:

Now we must configure our network and security settings:
Note that the VPC you choose must be your own.
I’ve elected to allow the console to create a new “subnet group” for me. This is not important for this demo.
I will let the console create a security group called “shineblog-neptune” – note this down for later.
I’ve left the default port of 8182. Our EC2 instance will communicate with the database on this port:
Once happy with the settings, go ahead and click “Create” to begin creating your cluster.
As per the below screenshot, when your database has finished creating it will show a status of “Available”
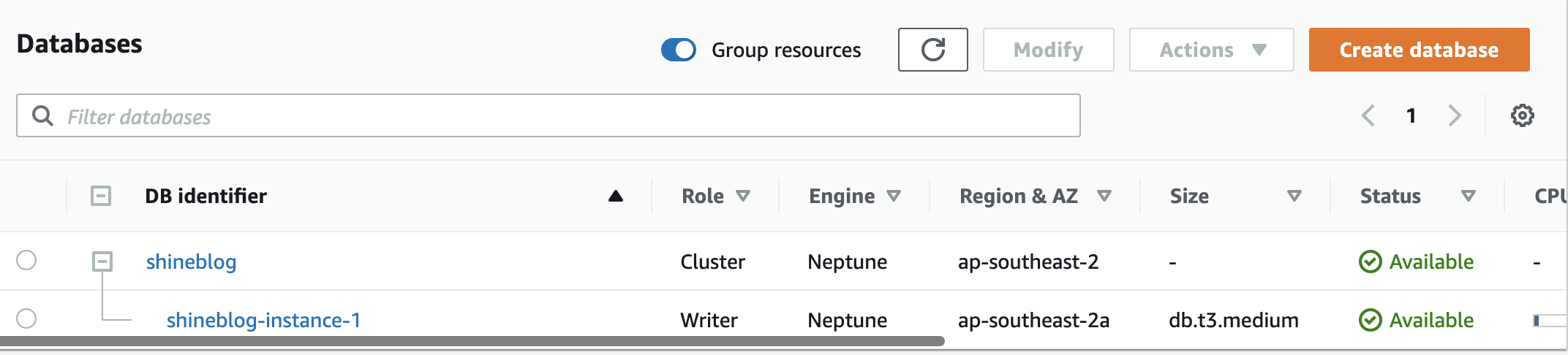
Click on the cluster and take note of the endpoint name for the writer, we will use this later to connect:

Security!
For our EC2 instance to be able to connect to this database, we will need to modify the database security group.
In the screenshot below, I’ve gone to our “shineblog-neptune” security group that is attached to our database instance. I have added a custom TCP rule to allow communication from our EC2 instance security group (shine-neptune-testing) on the default port 8182:
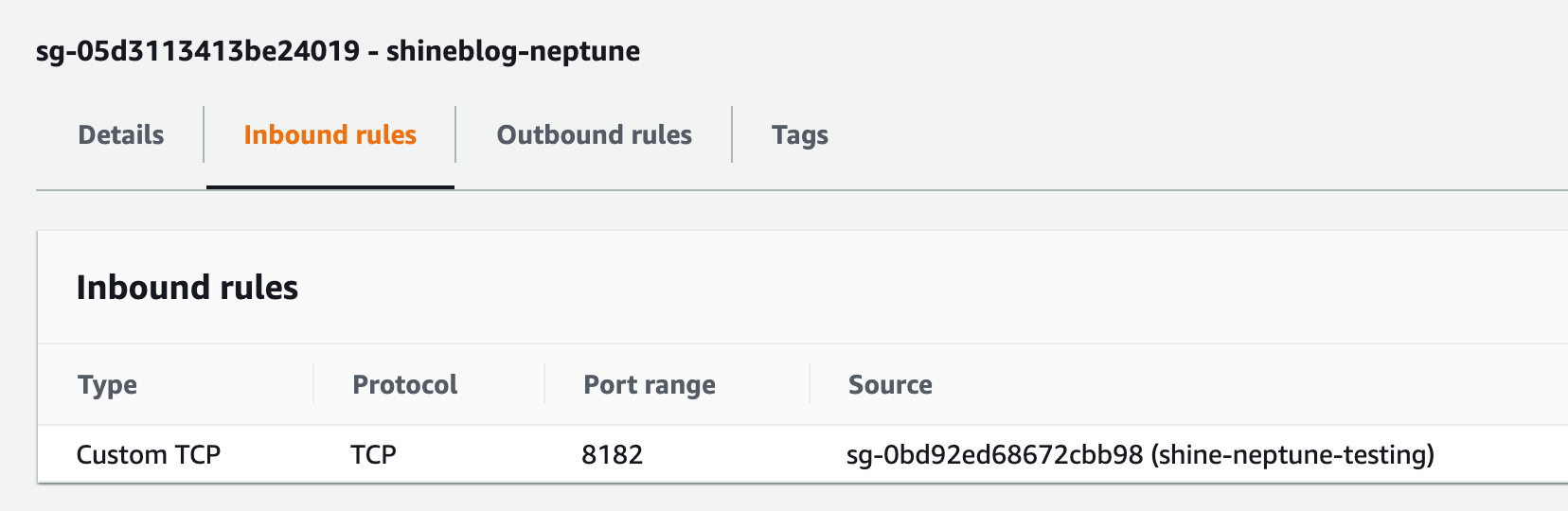
This should be enough from an infrastructure point of view to allow us to connect via the Gremlin console on our EC2 instance.
Connect to your EC2 instance
At this point you will want to connect to your EC2 instance. It’s out of the scope of the article to show how to do that, but I will assume you either have SSH or SSM access.
You’ll need to install and setup the Gremlin console on your instance.. I will suggest heading to this document and following the steps.
A couple of points in that document I found confusing or incorrect:
- In step 6.c they mention the JRE path “jre_path“. On my instance this was /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.amzn2.0.1.x86_64/jre. I found it by running the command
sudo /usr/sbin/alternatives --config java - The keytool command mentions Gremlin console 3.4.8, this should be 3.4.10 if you follow the steps. They also reference /home/ec2-user; that would be /home/ssm-user if you are connecting with session manager
- Step 7 mentions “your-neptune-endpoint”. This would be the cluster endpoint I mentioned you should take note of above.
If you have made it this far
We should now be in a position to connect from our instance to our Neptune cluster:


Looks good!
One important thing to note before moving on is that the Gremlin implementation running on Neptune does have some differences. They are outlined in this document here.
Sadly, we can’t import from our existing GraphML file across a remote connection. I had to convert the logic and data in our GraphML file into a series of statements we can run from the Gremlin console. You can find the file here. In that file the first block of commands inserts the nodes with their relevant data properties. The second block inserts the edges that map relationships between nodes. You can simple copy and paste it into your Gremlin console running on the EC2 instance.
Other ways to import data
There are multiple options available for importing data to Neptune. Some of the options are:
- Adding/modifying/deleting via Gremlin console – this is really only for exploration purposes and isn’t useful in a real-life case
- Using the Neptune bulk loader to get data from S3 – useful for batch ingestion. Requires an S3 VPC Endpoint and correct permissions
- Using AWS Database Migration Service – useful for initial match ingestion and continuing replication of data
- Programatically – for example via the Java Gremlin Client
Querying our graph in Neptune
Let’s see the same queries as above, but now being sent remotely from our EC2 instance. to our live Neptune database and being executed on there:


![gremlin>
g.V()•
has( 'name' , 'Account Service' ) .
repeat (out( ) . simplepath( ) ) .
until (has( ' name' , ' Customer Database' ) ) .
limit( 10).
path( ) . ' name' )
[Account Service, Proxy, Inter—site VPN, Customer Database]
Service, Legacy Account Service, Proxy, Inter—site VPN, Customer Database]](https://i0.wp.com/shinesolutions.com/wp-content/uploads/2021/02/image-25.png?ssl=1)

Wrapping up
Phew, we made it! Before continuing, don’t forget to terminate your cluster. There is no free tier, and Neptune isn’t particularly cheap.
So to sum up, Graph Databases offer some powerful ways to make connections between your data entities. I have really only scratched the surface of what is possible with Gremlin. If you are interested in going a bit deeper it’s hard to go past Kelvin Lawrence’s fantastic Gremlin tutorial. Many of the examples on airport data really set off some lightbulb moments for me, Hopefully, they do for you, too.
Links
http://www.kelvinlawrence.net/book/PracticalGremlin.html
https://tinkerpop.apache.org/docs/current/reference/#_tinkerpop_documentation
A Skeptic’s Guide to Graph Databases
TinkerPop 2020 (talk on history of Gremlin and TInkerPop)
TinkerPop Homepage (checkout the supported databases and client drivers)
No Comments