

12 May 2021 A Pragmatic Approach to Removing Known Vulnerabilities in Software
Upgrading software dependencies to remove known vulnerabilities is important but it can be painful. No engineer likes to do it and it takes time that would otherwise be spent delivering new features. Many organisations ignore the problem, or don’t even realise they have a problem, leaving themselves exposed to security breaches. A pragmatic approach is needed.
DevSecOps approaches, healthy CI/CD practices, and tools such as dependabot, make life much easier, but ultimately don’t fix everything. A large volume of breaking changes and packages with no fix available remain.
How do we assess what’s left? What is the risk exposure? How can we reduce the risk to an acceptable level without spending too much time? Assessing and fixing everything can be a huge drain. Especially for mature teams with numerous long lived projects.
Below is an approach to tackling this problem that we’ve used successfully at Shine. It is a risk-based approach that ensures the most important items are remediated promptly and doesn’t waste time on the rest. This approach can be tailored to match the risk profile and appetite of your organisation.
What are known vulnerabilities? What happens if we do nothing?
Known vulnerabilities or “Common Vulnerabilities and Exposures (CVEs)” are vulnerabilities that have been detected and registered publicly in the CVE list that is overseen by MITRE.
The OWASP list “using software components with known vulnerabilities” in their OWASP Top 10. It’s true that in many situations CVEs are harmless, however there are countless well documented security breaches that have involved attackers exploiting known vulnerabilities in dependencies.
There is no guarantee that your automation (assuming you have any) will fix all issues, or even the worst issues. In fact, quite the opposite. The vulnerabilities your automation can’t fix are the ones that require breaking changes to upgrade, or even significant rewrites. They are often the oldest packages with the most severe vulnerabilities.
Even if you’ve kept on top of things right from the start with good automation, the time will come eventually when manual intervention is required in order to remove vulnerabilities.
If you do nothing, you leave yourself at significant risk of a security breach. It’s for this reason that organisations should have a sensible policy on vulnerabilities. As we shall see however, the devil is in the details.
First, automate what you can (just don’t be fooled)
Although you can’t completely eliminate the overhead associated with remediation of vulnerabilities, you can reduce it through automation.
The automated approach below will mean in many situations you will be automatically notified a package is vulnerable, automatically provided with a pull request to approve, and then be able to automatically test and release the fix to production. We divide the approach into three stages:
Detect
The key with detection is to ensure your vulnerability scanning runs automatically on code repositories themselves or as part of CI/CD pipelines, as opposed to relying on less frequent and manually triggered external scans. You will find out about issues earlier and even prevent some issues by letting developers know the components they have introduced contain vulnerabilities before they are released to production.
There are many options for this depending on your current eco-system. dependabot, snyk, Sonatype Nexus, OWASP Dependency Check are all examples of tools you can use to achieve this task.
External scans can still be useful as a governance mechanism to ensure your automated processes are configured and working correctly.
Remediate
The next stage is remediation. Automation can be used to resolve these issues in many situations. renovate, dependabot, snyk, are some examples that can be used to this end. However as mentioned, don’t be fooled into thinking this is enough on its own. We will explore this in more detail below.
Release
Finally we release our remediated software. Healthy CI/CD practices such as sufficient automated test coverage, production monitoring and automated release processes reduce the friction of getting these fixes to production. These things should already be on your radar anyway.
What’s left? A lot, I’m afraid
Unfortunately, even with the most mature automation possible, it is simply not feasible or even possible to have zero vulnerabilities in production, all of the time.
As mentioned, an automated approach does not help when:
- The package is vulnerable, but no secure version exists yet
- There is a secure version, but it involves a significant upgrade with breaking changes
- There is no secure version and it’s unlikely there ever will be
Our experience is that non-breaking fixes are available only 50% to 90% of the time, depending on the situation. Newer projects that use technologies and dependencies that adhere to semver are able to be fixed automatically more often. Older projects using dependencies that do not adhere to semver, less so.
The rate at which CVEs are being found, along with the average number of dependencies in use by a given software project are both increasing over time. New vulnerabilities are often found in projects just days after being fixed. The associated effort is ever increasing. We found at one client that an average of 20 – 40 new vulnerabilities were being found per app, per month. This client had over 100 source code repositories to maintain. Things quickly become overwhelming.
CVEs discovered per year
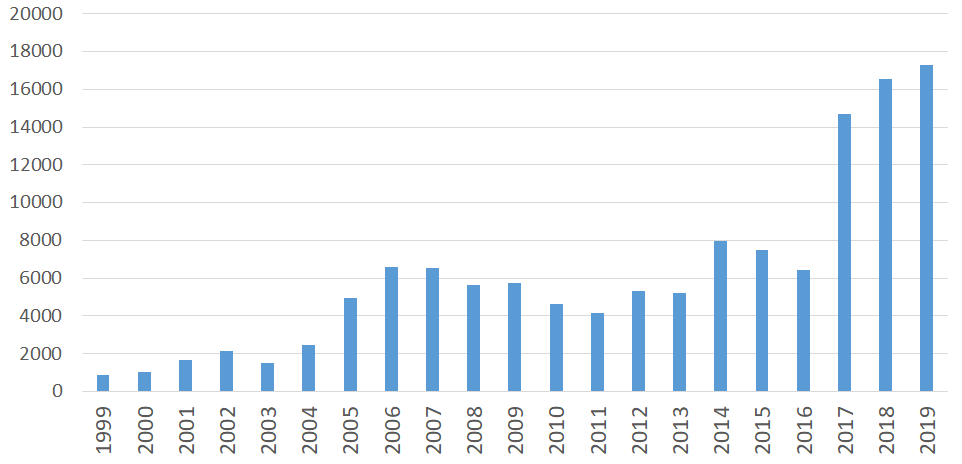
Image: debricked.com “What is a CVE?”
Even in situations where automation can be used, fixes are not available immediately. Often it takes time for a fix to be developed. In the meantime, we have to ask ourselves some important questions. What is our risk exposure? Is it acceptable to wait for the fix to be released, or should we be taking other measures like replacing the package? How long should we wait?
CVEs have different levels of risk, many have none at all
A good starting point to determine the risk posed by a given vulnerability is the CVSS score. CVEs are assigned a severity score using the Common Vulnerability Scoring System (CVSS).
However, the CVSS score alone is not enough to determine the risk posed by a given vulnerability, asit doesn’t take into account the context of your particular situation. Who can access the application that contains the vulnerability? What sort of data does this application deal with? A critical vulnerability in a private application that contains no sensitive data poses less risk than a publicly available app that handles large amounts of sensitive data.
In addition, there are many situations in which a vulnerability doesn’t pose any risk, regardless of the application. These include:
“Dev” Dependencies
These are when the component contains a vulnerability but is only used during build and is not actually deployed to production. Examples of these are compilers, linters and test frameworks. Occasionally these can pose a real risk if the vulnerability exploits the build pipeline itself (by mining cryptocurrency for example). However in the vast majority of situations, vulnerabilities in dev dependencies pose little risk.
False Positives
Often scanners will incorrectly detect vulnerabilities. For example when the vulnerability exists in the .NET version of a library but we are using the Java version.
Issues with functionality that is not used or that has been mitigated elsewhere
Often a vulnerability will apply only if you are using a specific feature of a particular dependency. If your logging software contains a vulnerability in it’s remote logger, but you are only using local logging, for example, the vulnerability poses no risk to you.
You might say, “Just because we don’t use that right now, doesn’t mean we won’t use it in the future.” Whilst this may be a valid argument, asking your engineers and product owners to spend valuable resources on upgrading a dependency on the off chance it may pose a risk in the future, is not very sensible. If you are worried about this, consider a regular review of your waivers to ensure they are still valid, or make them expire after a set period of time.
Focus your efforts using a risk-based approach
Given that a “zero tolerance” approach is neither realistic nor a sensible use of your precious engineering resources, consider an approach that defines targets based on the level of risk. Or to put in another way, give your teams longer to fix lower priority issues, but make sure high priority ones get fixed quickly.
You may be able to get away with a “fix everything immediately” approach on a newer team, or a smaller project, but it will become increasingly difficult as things get older and more complex. Developers will start to complain, and things will start to take longer.
Demonstrated below is a more nuanced approach. The specific classifications and targets can be tailored to your organisation.
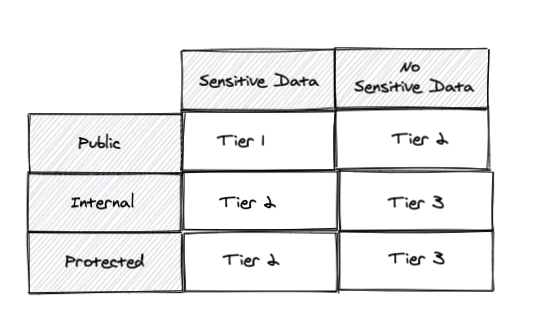
1. Classify the risk profile of your apps:
Start by classifying the risk profile of your apps. Specifically, consider how they are accessible and what sort of data they deal with:
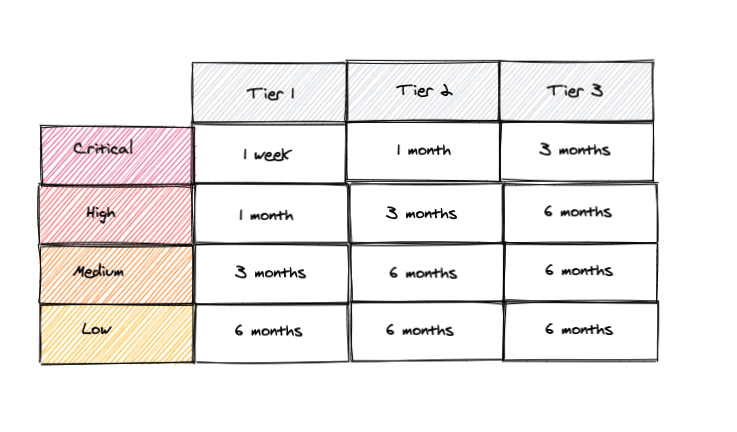
2. Define targets based on the CVSS score and the risk classification of the app:
The goal is to focus on the issues that pose the most risk and save time and effort on the rest. By extending the target for lower priority issues, we can save through economies of scale, and allow more time for the open source community to develop fixes. It is much more cost effective to upgrade, test and release an application once, fixing multiple vulnerabilities at the same time, than it is to do it for each vulnerability as it arises.
3. Automate reporting
Manually keeping track of everything above is impossible. Thankfully most scanning tools provide APIs that can be used to generate automated reports.

4. Empower engineers to “waive” vulnerabilities that pose no risk:
Engineers should be empowered with the discretion to waive vulnerabilities that pose no risk due to one of the reasons listed above.
The point isn’t necessarily to postpone upgrading indefinitely, but instead until a time that suits the team, just like any other dependency. In the meantime these vulnerabilities should not appear in reports.
This may seem like it could be abused, or you may feel like developers can’t be trusted to make these determinations. The reality is that you are already entrusting your engineers with many security concerns every day. This task is arguably much less difficult to get wrong than many of the other security related responsibilities your engineers already have.
You can also ensure waivers are peer reviewed or even add a regular “waiver review” session with your security team to help mitigate this risk.
5. Evaluate the effort and risk of those items remaining
For those items remaining, a decision needs to be made as to whether it’s worth the time to make the necessary changes or whether the organisation is ok to accept the risk.
This decision should involve engineers to evaluate the risk and effort to remediate, and a Product Owner or equivalent to make a priority decision. You may wish this decision to also be approved by your security team, depending on your organisation.
For example, if an internal application that does not handle sensitive data has a low severity CVE that would take weeks of development effort to remediate, perhaps it’s not the best use of the organisation’s resources?
6. Document for other teams
Once you have made the decision to put the work in to perform a particular upgrade on a particular app, it is important to have an agreed and communicated mechanism to record any learnings.
Putting it all together
Now that you have all the pieces of the puzzle you can put together a process for your teams to follow:

We have found this process to significantly lowers the overhead for teams whilst retaining a level of risk exposure that is acceptable. This process can be integrated with the existing delivery process used by your team. A ticket can be raised once an app has a vulnerability that is approaching its target and the team doesn’t need to worry about anything the rest of the time.
Conclusion
Solving this problem for your organisation is not trivial but it is achievable. The reality today is that many teams and organisations are simply not on top of things and/or are completely overwhelmed when it comes to vulnerabilities. By taking a more pragmatic approach you can reduce the effort required to a manageable level and get back to delivering value.
No Comments